
【新卒1年目でKaggle銀メダル獲得】 受賞者4名にインタビュー!
こんにちは、株式会社D4cプレミアムのデータサイエンティスト、キャリア入社2年目の銭です。2025年に開催されたKaggle(カグル)のコンペで、新卒1年目の社員4名がチームを組み、世界中のデータサイエンティストが競う中で銀メダルを獲得しました!
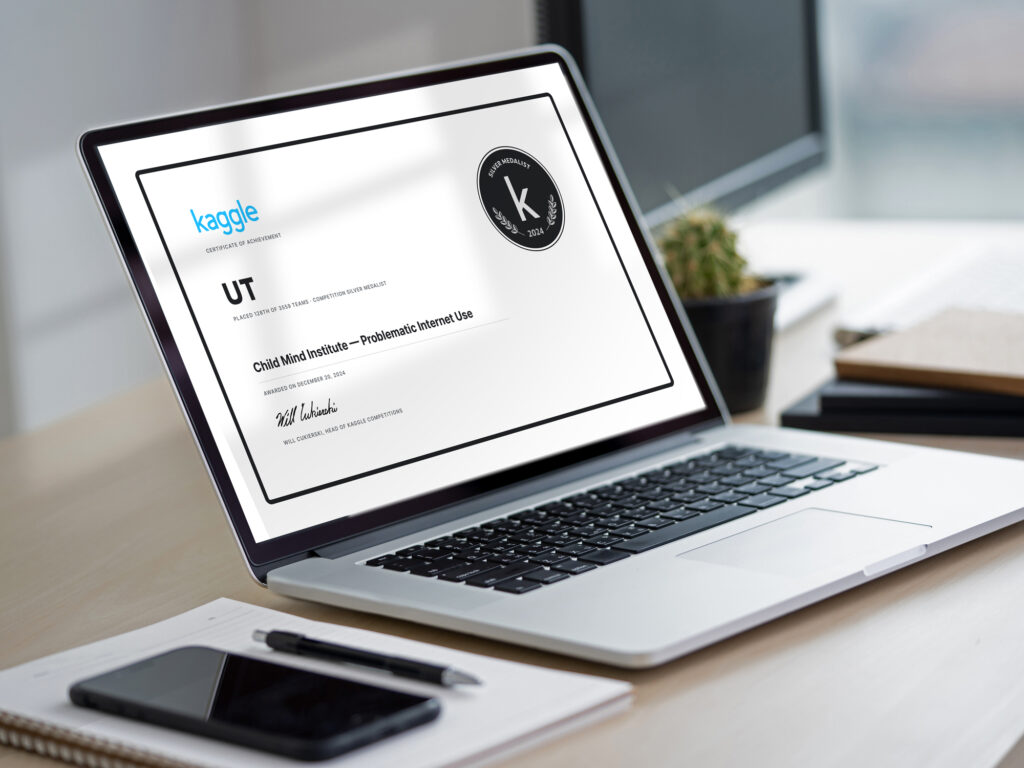
そこで今回は、銀メダルを獲得した社員4名(逢坂さん、池田さん、梅田さん、原田さん)にメダル獲得の秘訣や今後の抱負をインタビューしました。
Kaggleとは
Kaggleはデータサイエンティストや機械学習エンジニアが集う、世界最大級のオンラインプラットフォームです。企業や研究機関が現実世界の課題とデータセットを提示し、世界中の参加者がその予測精度を競い合います。画像認識・自然言語処理・時系列予測・不正検知など、多岐にわたる分野の課題が扱われ、自分の知識を試し、実践的なスキルを磨くことができます。
参加したコンペについて
今回4名の方が参加したコンペは「Child Mind Institute — Problematic Internet Use」です。
このコンペでは、5歳から22歳の子どもたちの姿勢や運動量といった身体活動データを用いて、インターネット利用における問題の早期兆候を検出する予測モデルの構築を目的としています。
具体的には、子どもたちの身長や体重、体力テストの結果を表形式にまとめたテーブルデータと、ウェアラブル端末を装着して取得した加速度センサーデータが説明変数として提供されています。
また、目的変数であるインターネット依存度は、保護者が回答したアンケート結果に基づき、4段階で評価されています。よって「子どもAはインターネット依存度が3、子どもBはインターネット依存度が1、…」と予測するモデルを構築していくことになります。
チームメンバー
— 皆さんの学生時代の専攻、また、プログラミングやデータ分析の経験やKaggleの参加経験の有無について教えてもらえますか。
逢坂さん:情報系の専攻で大学院を修了しました。プログラミングはある程度学習していましたが、Kaggleの参加経験はありませんでした。
池田さん:情報系の専攻で学部を卒業しました。学生時代にKaggleへの参加経験がありました。
梅田さん:言語学系の専攻で大学院を修了しました。プログラミングや分析経験としては、研究でRを使用した回帰分析を学んだ程度でした。
原田さん:農学系の専攻で大学院を修了しました。プログラミングは未経験でD4cプレミアムに入社しました。もちろんKaggleは参加したことがなかったです。

Kaggleに挑戦した理由
— 新卒1年目で大きなコンペに挑戦するというのはすごいことですね。挑戦したきっかけや想いなどを教えてください。
逢坂さん:技術力の向上のため以前から興味を持っていたものの、何回も一人で挑戦してはすぐ辞めることを繰り返していました。今回、同期たちと挑戦することでモチベーションを保つことができると思ったので挑戦しました。
池田さん:学生の頃から興味を持ち、個人で大会に参加していました。当時は一度挫折して期間が空いたのですが、会社でKaggleの褒賞制度※があることもあり、再び挑戦してみたいと思ったのがきっかけです。
※Kaggleにチャレンジし、高成績を収めたメンバーに対する給与・賞与の支給、および人事評価点の付与を行う制度。
梅田さん:私は、実務ではデータエンジニアリングを主に行っていますが、将来的に分析業務の幅を広げたいという目標がありました。Kaggleでの実績は社内外における「分析スキル」の客観的な証明になりますし、何よりメダル獲得が評価に直結する制度があることから、これを「業務に繋がるキャリア形成の一環」と捉え、参加を決めました。
原田さん:新卒1年目という今の時期だからこそ、まずは自身の技術力向上にしっかりと注力したいという強い思いがありました。また、同期に声をかけてもらったことも大きなきっかけです。一人でいきなりコンペに参加するのはハードルが高く感じられますが、仲間と一緒だったことでその心理的なハードルも下がり、思い切って挑戦することができました。
コンペの進め方や情報共有
— チームでの進め方や情報共有は、どのようにされていたのでしょうか。代表して梅田さんに伺いました。
梅田さん:まずは個人でコンペに取り組み、締め切りの1か月半前くらいにチームを組む形をとりました。 早くから合流しなかった一番の理由は、提出回数の制限です。この大会では、個人、もしくは、チームで1日5回までしか予測結果を提出できませんでした。そのため、チームを組む前なら各自が5回ずつ試行錯誤できるので、まずはその枠をフルに使って、個々人で自由に実験する時間を優先しました。
また、Kaggleの分析にはかなり時間がかかるので、最初から無理に全員の足並みを揃えるのではなく、各自の業務の状況に合わせて自分のペースで進めたかったという理由もあります。
— チーム結成後のコミュニケーションはどのように使い分けていましたか?
梅田さん:基本はSlackでのやり取りでしたが、情報の種類によってチャットとミーティングを使い分けていました。
・チャット:簡単な進捗報告
「ベストスコアを更新した」「この手法を試してみた」といった、日々の簡単な進捗や速報はSlackで行いました。チャットでリアルタイムに状況を共有しておくことで、お互いの動きをなんとなく把握している状態を作っていました。
・ミーティング:詳しい手法の共有
週に1〜2回のミーティングでは、チャットでは伝えきれない具体的な分析手法の中身や、今どんな課題があるかといった細かい進捗をじっくり報告し合いました。
それぞれが自分のペースで進めていたことで、自然と使っているモデルやアプローチに個性が分かれました。最終的には、それらを持ち寄って合わせる(アンサンブルする)ことで、結果として精度を大きく伸ばすことができたと感じています。
分析手法
— 最終的なモデルの構築に向けて、どのような方針をとったのでしょうか。
梅田さん:最終的な精度を最大化するため、私たちは「4人それぞれの試行錯誤から生まれた成果を最大限に活かし、最後にそれらを統合する(アンサンブル学習)」という手法をとりました。あえてバラバラの手法に挑戦することで、モデルに多様性を持たせ、お互いの弱点を補い合うことを狙いました。
— 皆さんは、具体的にどのような手法で分析を進めたのでしょうか。
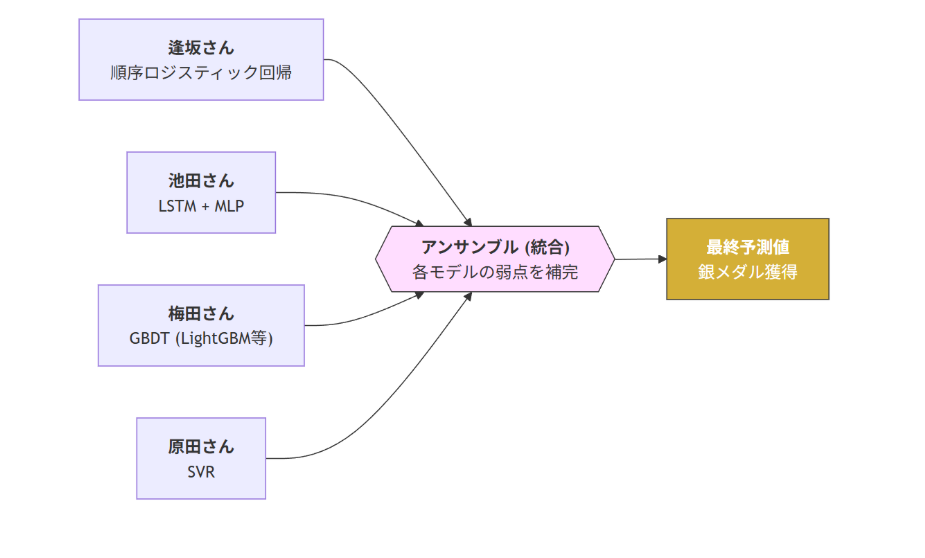
逢坂さん:前処理としてk近傍法による欠損値補完、標準化、変数同士の組み合わせによる特徴量作成を行いました。その後は変数同士で相関が高いものをグループ化して、各グループから一つずつモデルに使用する変数を選び、順序ロジスティック回帰で予測しました。
池田さん:前処理として欠損値補完、標準化、センサーデータからの日次データ作成などを行いました。その後はLSTM(Long Short-Term Memory)で30日分の日次データから特徴量を作成し、MLP(MultiLayer Perceptron)に時系列データと非時系列データを入力して予測しました。
梅田さん:前処理としてテーブルデータは変数同士を組み合わせてから、LightGBMで目的変数に対する重要度が高い上位100個の特徴量を選択しました。目的変数の欠損値は疑似ラベリングで補完しました。センサーデータは公開ノートブックのAutoencoderをそのまま使用し、最終的にLightGBM・XGBoost・CatBoostを使用して予測しました。
原田さん:前処理として欠損値の平均値補完、変数同士の組み合わせによる特徴量作成をしました。その後は目的変数との相関係数に基づいて特徴量を選択し、SVR(Support Vector Regression)を使用して予測しました。
【各メンバーの分析手法】
コンペ振り返り
— コンペを振り返ってみて、いかがですか?
逢坂さん:素直に嬉しかったです!ただし反省点もあります。実務でロジスティック回帰を使用したこともあり、理解をより深めたいという思いもありこの手法を選択したのですが、なかなか精度が上がりませんでした。精度を求める目的であれば、より適した手法があるのだということを実感しました。コンペ終了後に上位の解法を見ると、ドメイン知識も考慮したうえでの欠損値補完や異常値補完が重要だったので、特徴量エンジニアリングやドメイン知識も身につける必要があると感じました。
池田さん:CV(Cross Validation)とLeaderboardの相関があまりとれていない大会だったため、最終的な順位変動に備えて、より頑健なモデルの作成を念頭に置いておく必要があったように感じました。
梅田さん:メダルが取れるとは思っていなかったので、とても嬉しかったです!機械学習は研修以外で触れたことがなかったので、分析フローを学ぶ良い機会となりました。特に特徴量作成とアンサンブル学習についての知見を得ることができ、モデルの精度を上げるための基礎力が身についたと思います。また、チームで意見を交換しながら分析に取り組むことで、様々なアプローチを知ることができましたし、楽しく取り組むことができました。
原田さん:ほかのメンバーが決定木系のモデルや深層学習モデルを使うなかで、モデルに多角性を持たせることを意識しSVRを採用しましたが、モデルの精度はイマイチでした。アンサンブル学習や特徴量エンジニアリングの部分など、精度向上のために工夫できる点はあったので次回以降は作業スピードを上げて様々なアプローチに取り組みたいと思います。
今後に向け
— 今後の抱負について教えてください。
逢坂さん:Kaggleは今回のように実務で経験したことをアウトプットできる良い機会だと思っているので引き続き取り組みながら知識を蓄えていきたいです。
池田さん:引き続きKaggleに取り組み、データ加工の技術や、深層学習のスキル向上に努めたいです。
梅田さん:実務ではデータエンジニアリングを主に行っていますが、今回の経験を活かして分析業務にも取り組んでいきたいです。
原田さん:引き続きKaggleには積極的に参加しつつ、そこで学んだことを実務に活かしていきたいです。
最後に
今回はKaggleで銀メダルを獲得した新卒1年目の4名にインタビューしました。「Kaggleは実践的なデータを扱えるため、知識の定着を図る良い機会だった」とのお話が印象的でした。また、順位が高ければメダルを獲得できるので、ゲーム感覚で学ぶことができることもKaggleの魅力の一つかもしれません。
メダルを獲得した皆様おめでとうございます。今後の活躍を期待しています!
D4cプレミアムはKaggleへの挑戦を推進するため、定期的に、過去に提供されたKaggleのデータを使用し分析会を行っています。また、Kaggle MasterやKaggleメダル獲得者には、メダルの種類に応じて報奨金が支給されるKaggle褒賞制度もあります。データサイエンティストにとってノウハウの共有や社外コンペへの参加は、自己成長に直結します。D4cプレミアムには、自身のスキルを磨いて高みを目指したい方にとっての環境が整っていますので、ぜひご応募をお待ちしています!
(書き手:銭)







